What’s New in Data Replication
Much of what’s new for
Microsoft SQL Server data replication revolves around simplifying setup,
administration, and monitoring of a data replication topology. This is
the result of years of practical experience and thousands of production
replication implementations around the globe. The overall data
replication approach that Microsoft has developed (since replication’s
inception back in SQL Server 6.5 days) has been so solid that
competitors, such as Oracle (with its Oracle Streams technology), have
tried to mimic this architectural approach.
Among many others, the
following are some of the new replications features and enhancements
that make SQL Server 2008 data replication one of the best data
distributions tools on the market:
Highly available replication node additions— SQL Server 2008 offers the capability to add nodes to a replication topology without quiescing the topology.
Topology Viewer—
Enhancements have been made to the Peer-to-Peer Topology Wizard so that
you can now visually see what the peer-to-peer topology looks like with
the Topology Viewer.
Capability to centrally monitor all agents and jobs at the Publisher— You are able to view information about all the agents and jobs associated with publications at the selected Publisher.
Minor Replication Monitor enhancements—
Replication Monitor has undergone slight tweaks to make it easier to
monitor your full replication topologies. It allows you to monitor the
overall health of a replication topology and provides detailed
information about the status and performance of publications and
subscriptions.
Capability to replicate switch partition ALTER—
Enhanced Transactional Replication Support for Partitioned Tables is
now available, including the capability to replicate the switch
partition ALTER for Tables.
Scripting integrated into wizards— You can almost completely script your replication setup or breakdown during or after wizard executions.
Conflict Viewer—
This feature helps you view and resolve any conflicts that occurred
during the synchronization of a merge subscription or queued updating
subscription.
Peer-to-peer transactional replication—
Further enhancements have been introduced to the peer-to-peer
replication model. They allow replication between identical participants
in the topology (a master/master or symmetric publisher concept).
Peer-to-peer conflict detection— The capability to detect conflicts during synchronization in a peer-to-peer replication topology has been added.
More replication mobility— Merge
replication provides the capability to replicate data over HTTPS with
the web synchronization option, which is useful for synchronizing data
from mobile users over the Internet or synchronizing data between
Microsoft SQL Server databases across a corporate firewall.
Microsoft Sync Framework—
This comprehensive synchronization platform enables collaboration and
offline access for applications, services, and devices. It features
technologies and tools that enable roaming, sharing, and taking data
offline. By using Sync Framework, developers can build sync ecosystems
that integrate any application with any data from any store that uses
any protocol over any network. We mention it here because of its
replication-like behavior for “occasionally connected” applications.
What Is Replication?
Long before you ever start
setting up and using SQL Server data replication, you need to have a
solid grasp of what data replication is and how it can be used to meet
your company’s needs. In its classic definition, data replication is
based on the “store-and-forward” data distribution model, as shown in Figure 1.
In other words, data that is inserted, updated, or deleted in one
location (stored) is automatically distributed (forwarded) to one or
more locations.
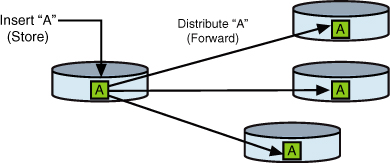
Of course, the data
distribution model addresses all the other complexities of updates,
deletes, data latency, autonomy, and so on. It is this data distribution
model that Microsoft’s data replication facility serves to implement.
It has come a long way since the early days of Microsoft SQL Server
replication (earlier than 6.5) and is now easily categorized as
“production worthy.” Numerous worldwide data replication scenarios have
been implemented for some of the biggest companies in the world without a
hitch. These scenarios fall into five major types:
Offloading—
You might need to deliver data to different locations to eliminate
network traffic and unnecessary load on a single server (for example,
when you need to isolate reporting activity away from your online
transaction processing). The industry trend is to create an operational
data store (ODS) data architecture that replicates core transactional
data to a separate platform in real-time and delivers the data to the
reporting systems, web services, and other data consumers without
impacting the transactional systems in any way.
Enabling—
You might need to enable a group of users with a copy of data or a
subset of data (vertically or horizontally) for their private use.
Partitioning—
You might need to move data off a single server onto several other
servers to provide for high availability and decentralization of data
(or partitioning of data). This might be the basis of serving customer
call centers around the globe that must service “active” support calls
(partitioned on active versus closed service requests).
Regionalization—
You might have regional ownership of data (for example, regional
customers and their orders). In this case, it is possible to set up data
replication to replicate data bidirectionally from two or more
publishers of the same data.
Failover—
You could be replicating all data on a server to another server (that
is, a failover server) so that if the primary server crashes, users can
switch to the failover server quickly and continue to work with little
downtime or data loss.
Figure 2 illustrates the topology of some of these replication variations.
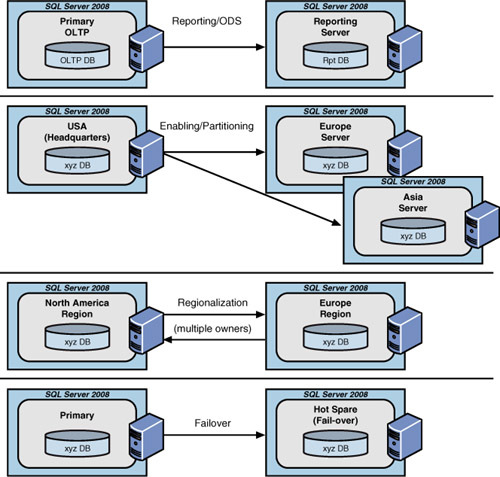
As
you may notice, you can use data replication for many reasons . First, however, you
need to understand some of the common terms and metaphors Microsoft uses
in relationship to data replication. They started with the “magazine”
concept as the basis of the metaphor. A magazine is created by a
publisher, distributed via the mail, and delivered to only those who
have a subscription to the magazine. The frequency of the magazine
publication can vary, as can the frequency of the subscription
(depending on how often the subscriber wants to receive a new magazine).
The publication (magazine) consists of one or more articles. One or
more articles can be subscribed to.